Linux系统调用一定比库函数效率高吗——预读入缓输出机制
Linux系统调用一定比库函数效率高吗——预读入缓输出机制
Q:如果一个只读一个字节实现文件拷贝,使用系统函数(read、write)效率高,还是使用对应的标库函数(fgetc、fputc)效率高呢?
实际代码测试
采用系统函数read,write
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| #include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#define N 1
int main(int argc, char* argv[])
{
char buf[N];
int fd_in = open(argv[1], O_RDONLY);
int fd_out = open(argv[2], O_WRONLY | O_CREAT | O_TRUNC, 0775);
if (fd_in == -1 || fd_out == -1)
{
perror("open error");
exit(1);
}
int n;
while ((n = read(fd_in, buf, N)) != 0)
{
if (n < 0)
{
perror("read error");
exit(1);
}
write(fd_out, buf, n);
}
close(fd_in);
close(fd_out);
}
|
采用库函数fgetc和fputc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[])
{
FILE* fp_in, * fp_out;
int n;
fp_in = fopen(argv[1], "r");
fp_out = fopen(argv[2], "w");
if (fp_in == NULL || fp_out == NULL)
{
perror("fopen error");
exit(1);
}
while ((n = fgetc(fp_in)) != EOF)
{
fputc(n, fp_out);
}
fclose(fp_in);
fclose(fp_out);
}
|
实际运行结果
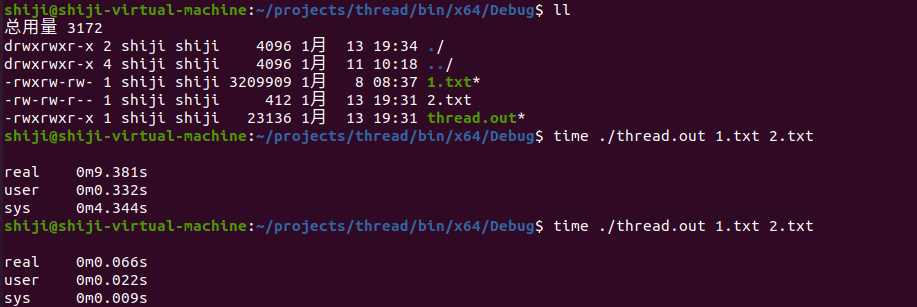
第一次为系统函数,第二次为库函数结果,速度有很明显的差别
原因分析
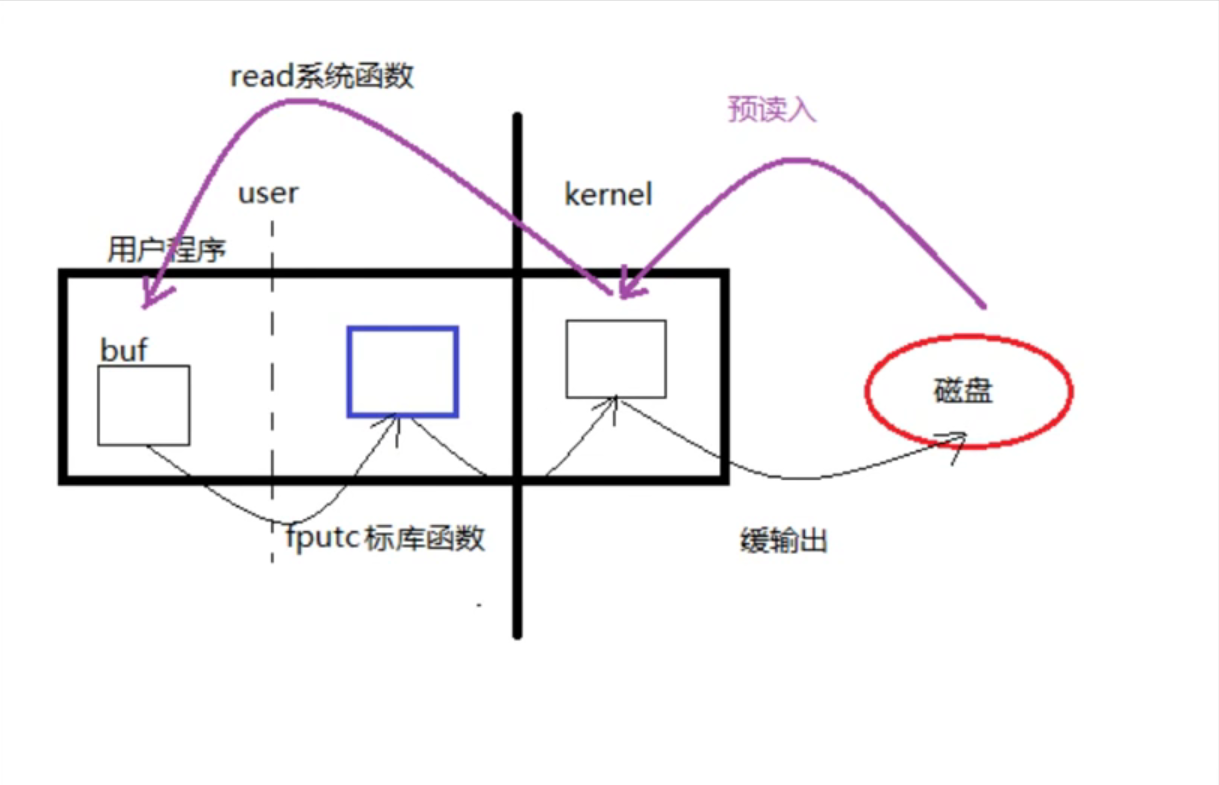
采用库函数时,虽然我们给定的缓冲区只有1个字符的大小。但fputc和fgetc的库函数在调用时会自动创建大小为4K的缓冲区,只有当读满后,才会写入核心中的缓冲区,切换访问权级的次数较少。
而当我们仅采用系统调用的时候,没有了库函数提供的缓冲区,因此只能一个字符一个字符的向核心中的缓冲区内写入,每写入一次都要发生权级切换,性能开销极大。
因此可以通过适当加大缓冲区(4K),或者是直接采用库函数的方式来提高性能